Tecnologías
El principio de siglo nos ha permitido asistir a un ejemplo más de la imparable
evolución de la Web. Lo que en los años 80 fue la revolución de una Internet
que hoy vemos limitada, e incluso pobre, en los 90 deja de ser un espacio que
meramente proveía protocolos de interconexión y se convierte en un espacio
integrado, la World Wide Web (Web 1.0). Desde la explosión de la burbuja de
Internet (2001) se da un paso más en la evolución ofreciendo una nueva red de
servicios, Web 2.0, que enfatiza la colaboración en línea y la compartición de
la información de los usuarios en lo que hoy podemos decir es la versión más
social de la Web (weblogs o bitácoras, podcasts, RSS, wikis, etc.) que podemos
encontrar en sitios como Wikipedia, eBay, Digg (o Meneame), Flickr y AdSense,
etc. Si la Web 1.0 se sustentaba en la simple presentación de información útil,
en su versión evolucionada adquiere una actitud coparticipativa en la que la
inteligencia en el uso de la información la ponen los usuarios en continuo
contacto y colaboración.
Nos enfrentamos hoy (hasta 2020 en la línea de
predicción de Nova Spivack, Radar Networks,ver Figura) a la nueva fase evolutiva
de la Web, la Web 3.0. Es difícil definir la Web 3.0, especialmente si tenemos
en cuenta que precisamente la Web 3.0 es lo que resta por definir desde hoy en
adelante. Sin embargo, en sus primeros pasos se construirá de la amalgama de
diversos conceptos, algunos heredados o evolucionados de la Web 2.0 y otros
trasladados o adaptados de la Web Semántica. La inteligencia en el uso de la
información deja de recaer enteramente en la capacidad humana de relacionar y
razonar. La Web dejar de ser una interfaz para presentar información, más o
menos rica, más o menos flexible, y aparece la inteligencia Web.
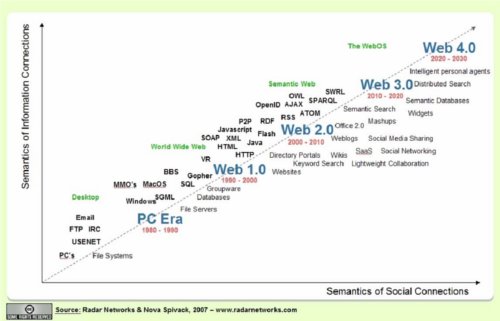
Dejamos atrás la Web interpretada por humanos (HTML) y buscamos la Web
interpretada por máquinas (RDF, XML, OWL, etc.). Se trata de una Web
inteligente, capaz de entender el lenguaje natural y buscar datos con la mínima
intervención humana, impulsando un nuevo estilo de vida y comportamiento. Más
allá de la Web 3.0., Spivack sitúa otro concepto, el de WebOS, que podría
marcar el paso a la Web 4.0. Una visión futurista en la que las máquinas
inteligentes podrán combinar las habilidades que hoy sólo caracterizan a la
mente humana (fundamentalmente nuestra potencia en el reconocimiento de
patrones) con aquellas otras habilidades en las que las máquinas son, ya hoy,
superiores (como recordar y buscar en cantidades ingentes de información).
En este camino en la búsqueda de una Web 3.0 plena, el esfuerzo ha de ser
progresivo. En este contexto se sitúa este proyecto que pretende el despliegue
de un servicio social (baluarte de la Web 2.0) apoyado en un sustrato semántico
que permita resolver algunos de los inconvenientes del la Web 2.0.
Por otro lado, garantizar al máximo la socialización del
servicio implica el acceso ubicuo y universal al mismo, plano que se incorpora
al proyecto mediante la propuesta de un servicio de acceso multimodal (TV, PC,
dispositivo móvil).
En este apartado se describirá cuál es el estado del arte
en las diferentes tecnologías que intervienen de forma relevante en el
desarrollo del presente proyecto. Dado que en este proyecto se inspira, en gran
medida, en la filosofía cooperativa y social de la Web 2.0, ofrecemos una
visión general sobre esta nueva forma de ver la Web, su
alcance, sus ventajas y la situación actual. El puntal de la Web social es el
establecimiento de comunidades virtuales que establecen vínculos entre
diferentes usuarios unidos por intereses y/o características comunes. En el uso
que esas comunidades hacen de los recursos de la Web y con el objetivo de
compartir tales recursos emergen diferentes descripciones libres (folksonomías)
de los mismos obtenidas de un esfuerzo colaborativo de la red social.
Sin embargo, el uso de un vocabulario libre sin un
sustrato semántico común acarrea dificultades de automatización de procesos en
la Web 2.0, siendo esta misma problemática la que originó los avances en Web
Semántica. A pesar de su discurrir paralelo, la socialización de la Web (en la
Web 2.0) se puede beneficiar del uso de tecnologías semánticas que mejoren la
compartición y acceso automático a recursos de interés. Es así que el uso de
ontologías se convierte en una herramienta clave en este proceso socializador y
aglutinador de sinergias individuales, proporcionando el sustrato semántico
para las folksonomías.
Por último, debido a que en un
contexto de redes sociales construidas entorno a intereses comunes la
recomendación automática adopta un papel relevante, dedicaremos los
apartados a analizar dos aspectos esenciales en cualquier proceso de
recomendación colaborativa: la
algoritmia o técnicas aplicadas para afrontar un proceso de este tipo y la caracterización de los
usuarios, respectivamente.
Por otro lado, el proyecto propone un servicio de acceso ubicuo y universal que
si bien ampliamente conocido en su acceso Web, presenta su aportación más
novedosa en el acceso mediante dispositivos móviles. El estándar DVB-H que será el utilizado para la difusión de la
información a todos los usuarios de receptores móviles suscritos al servicio de
distribución y etiquetado de contenidos.
Web 2.0
No se puede decir que exista una única definición del término Web 2.0 acuñado
por O'Reilly Media en 2004. Sin embargo, está generalmente aceptado que el
término hace referencia a una nueva generación de aplicaciones o servicios en
la web que fomentan la participación de los usuarios y la colaboración entre
los mismos. En su destacado artículo de 2005, Tim O'Reilly define lo que vienen
a ser los principios básicos de la Web 2.0: la web como plataforma, el
aprovechamiento de la inteligencia colectiva, la importancia de los datos como
fuente de ventajas competitivas, la versión "beta" perpetua, modelos ligeros de
programación, ubicuidad del software, e interfaces ricas para los
usuarios. Alrededor de esta serie de principios se sitúan otra serie de ideas,
aplicaciones o tecnologías propias de la Web 2.0.
La Web 2.0 supone un nuevo paradigma o evolución de la web que engloba un
conjunto de tendencias, técnicas y metodologías que han surgido en los últimos
años. En cualquier caso, es necesario diferenciar dos visiones o perspectivas
de la Web 2.0: aquella que plantea una nueva web por y para las personas, y
aquella que considera la web no ya como un servicio, sino como una plataforma
para desarrollar nuevas aplicaciones. En la primera visión, la Web 2.0 enfatiza
la participación de las personas a la hora de aportar: recursos, información, y
anotación (descripción) de recursos e información. Bajo la segunda visión, la
web debe construirse a partir de APIs interoperables y de modelos de confianza
para fomentar la libre participación y utilización de tecnologías de libre
acceso.
En cualquier caso, los principios clave que caracterizan la Web 2.0 son:
- Los datos y la información son el motor de las nuevas aplicaciones web.
- Efectos emergentes creados por arquitecturas de participación
- Nuevos modelos de negocios basados en la sindicación de servicios
- Aprovechar el valor del conjunto de empresas y usuarios que, aunque
quizá no sean de gran relevancia, pero que constituyen el grueso de los
participantes de la red.
Ejemplos representativos de la Web 2.0 son Google maps, que ofrece un API para
integrar y anotar mapas en cualquier aplicación web o Google Adsense que
presenta una arquitectura de publicación-suscripción que ejerce de mediador
entre un conjunto de empresas publicitarias y un conjunto de webs donde se
presentan los anuncios; BitTorrent, que permite la distribución de ficheros de
gran tamaño en aplicaciones P2P y que es la base para la Internet TV y otras
aplicaciones basadas en contenido audiovisual; y por último, Amazon Web
Services que aporta un conjunto de servicios web que resuelven funcionalidades
relevantes para aplicaciones de comercio electrónico. Para el usuario del web,
son relevantes, así mismo, Flickr, un famoso repositorio de fotos e imágenes
que pueden ser descritas y compartidas por todos los usuarios registrados en el
sistema o Del.icio.us, un repositorio compartido de URLs que se basa en los
enlaces proporcionados por los usuarios, también destaca Amazon.com, que
facilita recomendaciones a partir de las valoraciones y preferencias de los
usuarios o Wikipedia, que representa el paradigma de la construcción
cooperativa de conocimiento a partir de un sistema abierto de edición de
páginas web y, finalmente, la blogosfera, donde cada usuario aporta noticias y
recursos en su diario personal o blog.
La Web 2.0 también está asociada a la aparición de un conjunto de tecnologías
que son clave tanto para facilitar la participación de las personas como para
construir APIs interoperables:
- AJAX, que permite la construcción de interfaces gráficos ricos
- RSS, el lenguaje clave para sindicación y agregación de datos y noticias
- folksonomias, los vocabularios generados por la agregación de anotaciones
de los usuarios
- SOAP y REST, los protocolos básicos para crear la web como plataforma, y
los
- Mashups, la tecnología que permite construir nuevas mini - aplicaciones a
partir de la integración de APIs externos.
Modelos de negocio
Una de las características más reseñables de la Web 2.0 es la socialización de
la Red. Mientras en la web tradicional la mayoría de portales estaban
impulsados por organizaciones, instituciones o empresas, en la Web 2.0 el
impulso de las iniciativas se halla mucho más distribuido dado que el nuevo
motor de actividad en la web son las personas a título individual. En este
nuevo marco, ¿cuáles son entonces los nuevos modelos de negocio?
En el caso de las iniciativas 2.0 la estrategia para conseguir ingresos
directos derivados de la actividad depende mucho de si nos basamos en la
existencia de una audiencia (y cobramos a los que quieren contactar con ella) o
en una tecnología (y cobramos a la audiencia, los usuarios, por disponer de
ella).
En los primeros, los modelos basados en audiencia, se recalca el parecido cada
vez mayor de Internet con los canales de comunicación convencionales. Los
grandes paradigmas del movimiento Web 2.0 (del.icio.us donde la gente comparte
sus enlaces; Flickr, donde comparte fotografías y YouTube donde comparten
vídeos) basan su fuerza en la aportación de millones de personas, lo que a su
vez les proporciona millones de visitantes. Esta audiencia hace posible
plantearse un modelo de ingresos basado en publicidad. Otra opción de ingresos
económicos vinculada a parámetros de audiencia es la de las comisiones por
transacción. Si las personas que se desenvuelven en una propuesta web realizan
operaciones económicas entre ellas, normalmente de compra venta, el promotor
del sitio Web puede aspirar a una comisión sobre ellas (eBay es entonces el
ejemplo clásico, siendo, sin duda, Second Life el otro gran
ejemplo). Finalmente, el carácter social de muchas de las iniciativas
enmarcadas en Web 2.0 hace que en muchas ocasiones su público constituya una
audiencia con un alto grado de compromiso con el proyecto. Sus miembros o
usuarios son personas que contribuyen al éxito de la iniciativa mediante no
sólo aportación de contenidos sino contribuciones económicas (paradigma basado
en donaciones Wikipedia).
En el segundo grupo de modelos, aquellos basados en la capacidad de ofrecer
prestaciones avanzadas a los usuarios, encontramos en la Web 2.0 propuestas que
complementan o mejoran servicios que tienen una base gratuita y de libre
acceso. Por ejemplo, Pay for Premium Use que sólo cobraría en caso de acceso a
mayores capacidades o a nuevas prestaciones (tal es el caso de Flickr). Otra
opción plantea en explotar el servicio comercialmente sólo para uso
corporativo, ofreciéndose de manera gratuita sólo al público en general (como
ejemplo eConozco).
Comunidades Virtuales y Etiquetado Colaborativo
Una comunidad virtual o red social es la representación de una estructura de
relaciones sociales entre individuos. La red social indica de qué forman están
conectados los nodos (individuos) por medio de diversos indicadores de
familiaridad, que van desde "conocidos" hasta "miembros de una misma
familia". El análisis de redes sociales es hoy en día una técnica
imprescindible de estudio social. Una red social se configura como un conjunto
de nodos unidos entre sí por vértices que representan las relaciones entre
ellos. Sobre esa red se pueden estudiar múltiples parámetros que definen su
característica. Entre los más importantes se encuentran el grado de un nodo -el
número de enlaces que tiene con los demás nodos-, la centralidad -que indica la
importancia de un nodo dentro de la red-, el alcance -el grado en que cualquier
miembro de la red puede llegar a otros miembros-, o la cercanía -el grado en el
que un individuo se encuentra cerca de todos los otros miembros de la red. En
general, el análisis de redes sociales se realiza sobre comunidades
preexistentes. Pero el mismo análisis puede realizarse para crear comunidades y
relaciones sociales, empleando los resultados del análisis de redes sociales
como guía para su evolución. FOAF (Friend of a Friend) es el lenguaje más
empleado para el modelado de redes sociales. FOAF está basado en RDF y se
define empleando OWL. Fue diseñado para ser extensible y facilitar que sistemas
informáticos diversos pudiesen compartir datos. FOAF permite definir a una
persona e indicar a qué otras personas conoce.
En una red social, el etiquetado representa un esfuerzo de la comunidad de
usuarios donde cada usuario, en base principalmente a sus intereses, contribuye
directamente a la creación de una colección de metadatos compartida que,
progresivamente, mejora su riqueza expresiva y su utilidad. Si cada usuario
elige libremente el conjunto de etiquetas para un recurso, la colección refleja
las actitudes sociales de la comunidad de usuarios e implícitamente desprende
una organización compartida del espacio objetivo del etiquetado. Este proceso
de clasificación gestionado por una comunidad social es acuñado por Thomas
Vander Wal con el término folksonomy (folksonomía). El término folksonomía se
refiere a la definición progresiva y colaborativa de una categorización y
organización relajada del contenido. Es decir, una taxonomía relajada obtenida
de forma colaborativa. Este proceso, sin embargo, no está exento de problemas
consecuencia de la libertad en el etiquetado (problemas relacionados con
sinónimos, polisemias, errores sintácticos, niveles de precisión, etc.) y que
son consecuencia de la no inclusión de información semántica en el etiquetado.
Con el objetivo de mitigar los inconvenientes asociados al uso de folksonomías,
es posible utilizar la folksonomía emergente para obtener vocabularios
controlados o para enriquecer vocabularios ya existentes (identificando
omisiones o mal interpretaciones). Al margen de este uso combinado, en el
estado actual de la investigación podemos localizar diferentes propuestas
orientadas a la mejora en la utilidad del etiquetado colaborativo y las
folksononías en general.
- Clustering o agrupamiento de etiquetas: A medida que aumenta el número de
etiquetas, la tarea de explorarlas se vuelve cada vez más tediosa. El
clustering propone la agrupación de tareas ya sea a priori por parte de los
usuarios o a posteriori utilizando algoritmos específicos de clustering.
- Visualización: También con el objeto de mejorar el acceso a las etiquetas,
se han propuesto diferentes técnicas de visualización, por ejemplo Tagnautica,
que organizan el espacio de etiquetado de forma visual.
- Etiquetado colaborativo de múltiples medios: Bajo este encabezado se
recoge la tendencia a crear servicios que permitan el etiquetado colaborativo
cross-media, es decir servicios que indexan elementos de naturaleza variada
(como ejemplo Technorati)
En otro orden de cosas, los servicios de etiquetado colaborativo nacen de una
comunidad de usuarios fuertemente comprometidos que invierten tiempo en el
servicio y recomiendan su uso a otros usuarios. A pesar de los incentivos
utilizados en este tipo de servicios, se percibe cierta fatiga o desencanto
relacionados con:
- Naturaleza aislada de los servicios. Los servicios de etiquetado
colaborativo no son sólo crecientemente específicos sino que además tienen
difícil interconexión unos con otros.
- Escasa portabilidad consecuencia de la falta de normas abiertas. El tedioso
trabajo de etiquetar, mantener un perfil de usuario o de bookmarking
colaborativo sólo excepcionalmente puede ser reutilizado en otro ámbito.
- Ausencia de búsqueda multiservicio, consecuencia de la naturaleza aislada
de cada uno de los servicios de etiquetado colaborativo.
Ontologías
Una ontología se define como una especificación formal y explícita de una
conceptualización compartida. La conceptualización describe un modelo abstracto
de un fenómeno que ocurre en el mundo real al identificar los conceptos
importantes de ese fenómeno. El término "explícito" implica que los conceptos,
relaciones, funciones, axiomas que se utilizan para describir el modelo y sus
restricciones de uso están claramente definidos. El término "formal" describe
el hecho de que la ontología tiene que ser ejecutable por la computadora. Y el
término "compartida" refleja la noción de que una ontología recoge conocimiento
consensuado, es decir, que no es privativo de una persona sino que está
aceptado por todo un grupo.
Al principio de los años 90, las ontologías se construían principalmente
utilizando técnicas de representación del conocimiento basadas en marcos,
lógica de primer orden y lógica descriptiva. En 1993, Gruber identificó cinco
tipos de componentes: clases, relaciones, funciones, axiomas e instancias. Sin
embargo, en los últimos años, las técnicas de representación basadas en lógica
descriptiva se han consolidado en el contexto de la Web semántica, creándose
nuevos lenguajes como OIL, DAML+OIL y OWL. Los componentes que se utilizan para
modelar ontologías en lógica descriptiva son fundamentalmente conceptos, roles
e individuos.
Lenguajes de ontologías
Al comienzo de los años 90, se crearon un conjunto de lenguajes de ontologías
basados en paradigmas de representación del conocimiento. Algunos estaban
basados en lógica de primer orden con algunas extensiones, como KIF, mientras
otros combinaban los marcos con la lógica de primer orden, como CycL,
Ontolingua, OCML y Flogic, y otros utilizaban lógicas descriptivas, como
LOOM. También en este periodo se creó el protocolo OKBC para acceder a
ontologías implementadas en diferentes lenguajes basados en marcos.
El gran auge de Internet hizo que se crearan lenguajes de implementación de
ontologías para poder explotar las características de la Web. A estos lenguajes
se les conoce normalmente como lenguajes de la Web Semántica o lenguajes de
ontologías de marcado, dado que su sintaxis se basa en la sintaxis de los
lenguajes de marcado existentes, como HTML y XML, cuyo objetivo es la
presentación y el intercambio de datos, respectivamente. Los ejemplos más
sobresalientes de dichos lenguajes son: SHOE, XOL, RDF, RDF Schema, OIL,
DAML+OIL, y OWL. De todos ellos sólo RDF y RDF Schema, cuya combinación se
conoce normalmente como RDF(S), y OWL, están recibiendo respaldo de forma
activa, por parte del consorcio de la World Wide Web (W3C), y son
recomendaciones (estándares) de dicho consorcio.
Infraestructura tecnológica
Las primeras herramientas de desarrollo de ontologías se crearon a principios
de los años noventa proporcionando interfaces de usuario que ayudaban a
desarrollar ontologías en lenguajes basados en lógica. A finales de la década
de los noventa el número de herramientas se incrementó en gran medida y la
funcionalidad de las mismas se diversificó, distinguiéndose los siguientes
grupos en la literatura:
- Herramientas de desarrollo de ontologías. Este grupo incluye herramientas
y paquetes integrados que pueden ser utilizados para construir una nueva
ontología desde cero. Las más relevantes son: KAON, OilEd, Ontolingua Server,
OntoSaurus, Protégé, SWOOP, Topbraid Composer, WebODE y WebOnto.
- Herramientas de evaluación de ontologías. Son utilizadas para evaluar
aspectos de consistencia, corrección y redundancia en el contenido de las
ontologías. Como herramientas de evaluación de ontologías más importantes
podemos destacar: OntoAnalyser y OntoGenerator, ODEClean, y ONE-T.
- Herramientas de alineamiento y fusión de ontologías. Estas herramientas
son utilizadas para resolver el problema de fusión y alineamiento de diferentes
ontologías pertenecientes al mismo dominio. Dentro de este grupo, se destacan:
PROMPT que está integrado en Protégé-2000, Chimaera, FCA-Merge, GLUE, y los
módulos de fusión de ontologías de OBSERVER.
- Herramientas de anotación basadas en ontologías. Con estas herramientas el
usuario puede insertar instancias de conceptos y de relaciones en ontologías y
mantener de forma semi-automática la anotación (descripción) de páginas Web
basada en ontologías. Muchas de estas herramientas han aparecido recientemente
en el contexto de la Web Semántica. En este grupo, las herramientas más
importantes son: AeroDAML, COHSE, la suite KAcess, MnM, OntoAnnotate,
OntoMat-Annotizer, y SHOE Knowledge Annotator.
- Herramientas de consulta de ontologías y motores de inferencia. Éstas
permiten la consulta de ontologías de manera sencilla y llevan a cabo
inferencias con ellas. Normalmente están muy relacionadas con el lenguaje
utilizado en la implementación de las ontologías. Destacan: ICS-FORTH
RDFSuite, Sesame, Jena, KAON API, TRIPLE, Cerebra y Ontopia Knowledge Suite.
- Herramientas de aprendizaje de ontologías. Estas herramientas pueden
obtener ontologías desde textos en lenguaje natural, así como desde fuentes
semiestructuradas y bases de datos, utilizando para ello técnicas tanto del
campo de aprendizaje automático como del procesamiento de lenguaje natural,
pero actualmente no utilizan técnicas integradas. Destacan las siguientes
herramientas: ASIUM, DODDLE, OntoBuilder, OntoLearn, SVETLAN', TERMINAE y
Text-To- Onto.
Estrategias de recomendación
En la literatura podemos encontrar numerosos ámbitos para los que se hizo
preciso disponer de herramientas de personalización, lo que ha dado lugar a que
en los últimos años se propusieran una gran diversidad de enfoques para
implementar este tipo de herramientas. Emplearemos los término usuarios
activos para referirnos a los individuos para los que la herramienta de
recomendación elabora una sugerencia personalizada, y producto objetivo para
referirnos a aquellos productos sobre los que la herramienta de personalización
deberá decidir si son o no adecuados.
Además de técnicas de modelado de usuarios (sobre las que versará el siguiente
apartado), las herramientas de recomendación implementan diferentes estrategias
para seleccionar aquellos productos que mejor se ajustan a las preferencias y/o
necesidades de cada usuario. En la literatura, son cuatro los métodos de
filtrado de información más extendidos:
Filtrado demográfico
El filtrado demográfico emplea las características personales de los usuarios
(edad, sexo, estado civil, ocupación profesional, historiales de compra,
aficiones, etc.), que se proporcionan durante la fase de registro en el
sistema, para descubrir las relaciones existentes entre un determinado producto
y el tipo de usuarios interesados en él. Por su naturaleza, este método modela
las preferencias de los usuarios como un vector de características
demográficas, y recurre a la técnica de estereotipos para inicializar sus
perfiles. Así, todos aquellos usuarios que pertenezcan al mismo estereotipo
recibirán las mismas sugerencias por parte del sistema. El filtrado
demográfico adolece de dos limitaciones principales. Por una parte, puede
conducir a recomendaciones demasiado generales e imprecisas para los usuarios,
por considerar únicamente sus características demográficas. Además, este método
no permite que las sugerencias ofrecidas se adapten a posibles cambios en las
preferencias de los usuarios, dado que sus datos personales suelen permanecer
invariables a lo largo del tiempo. A pesar de los inconvenientes comentados, el
filtrado demográfico puede ser una estrategia útil si se combina con otros
métodos.
Métodos basados en contenido
Esta técnica consiste en recomendar a un usuario activo aquellos productos que
son similares a los que le han gustado en el pasado. Para ello, los perfiles de
los usuarios deben contener las características o atributos que definen dichos
productos. Si bien, por su propia naturaleza, es una estrategia muy precisa,
sus limitaciones más importantes son:
- Suele recomendar productos excesivamente parecidos a los que el usuario
activo ya conoce, e incluso, demasiado similares entre sí. En este último caso,
si alguno de los contenidos sugeridos no interesa al usuario, su confianza en
el sistema decrecerá rápidamente en virtud del excesivo parecido existente
entre éste y el resto de sugerencias ofrecidas. Esta limitación, denominada
sobre especialización, se debe al empleo de métricas de similitud para valorar
el parecido entre las preferencias de los usuarios y los productos objetivos.
- La especificación de los atributos requeridos en este método de filtrado es
una tarea muy costosa que puede exigir la participación de un experto que
proporcione tales descripciones.
- Otra de las limitaciones más conocidas de
los métodos basados en contenido es conocida con el nombre de new user ramp-up,
y está relacionada con la llegada de un nuevo usuario al sistema. En este
escenario, el recomendador suele disponer de muy poco conocimiento sobre sus
preferencias personales, de ahí la baja precisión de las recomendaciones
resultantes.
Filtrado colaborativo
Es una de las técnicas de filtrado de información más empleadas en las
herramientas de recomendación existentes. A diferencia de los métodos basados
en contenido, a la hora de ofrecer una recomendación a un usuario activo, el
filtrado colaborativo no considera sus preferencias personales, sino las de
otros usuarios con intereses similares a los suyos (llamados en adelante
vecinos). Esta similitud entre usuarios se estima a partir de las
clasificaciones (o índices de interés) asociadas a cada una de sus preferencias
en sus perfiles personales. Precisamente por ello, los enfoques colaborativos
prescinden de las descripciones de contenido (características de los productos
presentes en el perfil del usuario), requeridas en los métodos basados en
contenido.
En la literatura podemos encontrar dos técnicas diferentes para este tipo de
estrategia:
- Filtrado colaborativo basado en usuario: Sugiere a cada usuario activo
aquellos productos objetivo que han interesado a sus vecinos. Para formar este
vecindario, la estrategia considera que dos usuarios tienen preferencias
similares si han clasificado los mismos productos en sus perfiles y les han
asignado índices de interés parecidos.
- Filtrado colaborativo basado en item: Se recomienda un producto a un
usuario activo si es similar a los contenidos de su perfil personal. En este
caso, se considera que dos productos son similares si los usuarios que han
clasificado uno de ellos tienden a clasificar el otro, asignándole índices de
interés parecidos. Esta técnica da mejores resultados que la variante basada en
usuario cuando el número de productos activos presentes en la base de datos
usada en la recomendación es mucho menor que el número de usuarios.
Dados un usuario activo y un producto objetivo, un sistema colaborativo debe
predecir el nivel de interés del primero en relación a dicho producto, para así
poder decidir si éste debe o no ser sugerido al usuario. En dicho proceso,
podemos diferenciar tres fases. La primera tiene como objetivo seleccionar
aquellos usuarios cuyas preferencias son similares a las del usuario activo.
Por el contrario, los enfoques basados en ítem deben extraer aquellas
preferencias del usuario que son más similares al contenido objetivo. Para
medir tal similitud, este tipo de propuestas consideran las preferencias del
resto de usuarios del sistema colaborativo. A continuación, es necesario formar
el vecindario de este usuario (o de sus preferencias) a partir de la selección
realizada en la etapa anterior. Finalmente, el sistema debe predecir el nivel
de interés del usuario activo en relación al producto objetivo. Para ello, los
enfoques basados en usuario consideran el nivel de interés de los vecinos del
usuario activo en relación al producto objetivo. Por el contrario, la versión
colaborativa basada en ítem considera el nivel de interés del usuario activo en
relación a aquellos contenidos de su perfil que son más similares a dicho
producto objetivo.
Por su propia naturaleza, los enfoques colaborativos permiten superar la falta
de diversidad asociada a los métodos basados en contenido, ya que las
recomendaciones elaboradas no se basan únicamente en las preferencias del
usuario activo, sino que consideran los intereses del resto de usuarios del
sistema. Esta cualidad se aprecia fácilmente en el método colaborativo basado
en ítem, ya que en este caso, dos productos pueden ser similares (y por tanto
recomendados al usuario activo) aun cuando no compartan ningún atributo
semántico; simplemente es necesario que la mayoría de los usuarios del sistema
los hayan clasificado a la vez en sus perfiles. Sin embargo, en el filtrado
colaborativo también es posible identificar algunas limitaciones importantes:
- En primer lugar, el new user ramp-up sigue estando presente en este tipo
de sistemas, por la dificultad de formar el vecindario asociado a un usuario
que acaba de llegar al sistema, cuyo perfil registrará, típicamente, un número
muy reducido de preferencias.
- Otra limitación importante es el denominado sparsity problem, que se
produce cuando aumenta mucho el número de productos disponibles en la base de
datos usada en la elaboración de recomendaciones. Ante tal diversidad, es menos
probable que dos perfiles contengan exactamente los mismos productos
(preferencias) y, por consiguiente, es más difícil encontrar vecinos tanto para
el usuario activo como para el producto objetivo, fase crítica en los enfoques
colaborativos basados en usuario y en ítem, respectivamente.
- El tercero de los problemas ligados a los sistemas colaborativos es el
llamado gray sheep, especialmente perjudicial para aquellos usuarios que tienen
preferencias muy diferentes a las del resto de la comunidad. Estos usuarios
tendrán un vecindario muy reducido y, por ende, recibirán recomendaciones poco
precisas.
- Los problemas de escalabilidad también suponen un limitación muy
importante en los enfoques colaborativos tradicionales. Es evidente que a
medida que aumenta el número de productos y usuarios en el sistema, también se
incrementa la complejidad -- -computacional y temporal--- del proceso de
cálculo del vecindario de los usuarios activos y de los productos objetivo,
etapa crítica en este tipo de sistemas.
- Con el nombre new ítem ramp-up se identifica otra de las limitaciones de
los enfoques colaborativos, y que se produce cuando aparece un nuevo producto
objetivo. Habida cuenta que sólo se sugieren productos incluidos en los
perfiles de los usuarios del sistema, es necesario que este nuevo producto sea
clasificado por un número suficientemente elevado de usuarios antes de ser
recomendado. Como consecuencia de esto último, es posible identificar un tiempo
de latencia desde que el sistema conoce nuevos contenidos hasta que éstos son
sugeridos a los espectadores. Esta limitación es crítica en algunos dominios de
aplicación; por ejemplo, en el campo de la TV, donde continuamente aparecen
nuevos contenidos. Por esta razón, en los sistemas reales se deben reducir al
máximo sus efectos negativos, permitiendo así a los usuarios recibir sin
retardos innecesarios los programas más novedosos del momento.
- Por último, merece la pena destacar el llamado cold start, cuyos efectos
se manifiestan durante las primeras etapas de funcionamiento de los sistemas
colaborativos. Así, hasta que no se alcanza un número suficientemente elevado
de usuarios registrados, el recomendador no dispone de información suficiente
para crear de una forma precisa el vecindario (del usuario activo o del
producto objetivo), minando de esta forma la calidad de las sugerencias
ofrecidas.
Enfoques híbridos
Las limitaciones identificadas tanto en el filtrado demográfico, como en los
métodos basados en contenido y el filtrado colaborativo, plantearon la
necesidad de combinar varias de estas estrategias para así aunar sus ventajas y
neutralizar sus inconvenientes, incrementando así considerablemente la
precisión de las recomendaciones finales. Con esta premisa surgieron los
denominados sistemas híbridos.
Uno de los modelos híbridos que gozan de mayor popularidad es el que combina el
filtrado colaborativo y los métodos basados en contenido, en el que un producto
objetivo puede ser sugerido, bien porque es similar a las preferencias del
usuario activo, bien porque ha interesado a la mayoría de sus vecinos. Este
esquema permite que ambas estrategias se complementen en favor de la calidad de
las recomendaciones. Así, por ejemplo, un sistema híbrido es capaz de superar
el excesivo parecido existente entre las recomendaciones basadas en contenido y
las preferencias del usuario activo, gracias a que el enfoque colaborativo
incorpora la experiencia del resto de usuarios del sistema, diversificando así
las sugerencias ofrecidas. Por otra parte, el filtrado basado en contenido
elimina los tiempos de latencia requeridos en los sistemas colaborativos para
sugerir un producto nuevo. En un esquema híbrido, cualquier producto puede ser
recomendado sin retardo alguno, siempre que los métodos basados en contendido
consideren que se adapte a las preferencias personales del usuario activo.
Los diferentes enfoques híbridos propuestos en la literatura fueron evaluados
de forma exhaustiva por Robin Burke, quien identificó siete posibles modelos a
la hora de combinar estrategias de personalización de diferente naturaleza:
- Ponderado (Weighted): Decide si un determinado producto objetivo es
sugerido o no al usuario considerando las salidas de todas las estrategias de
recomendación (aunque puede que con pesos distintos para cada una de ellas) que
implementa.
- Conmutación (Switching): En este caso, en lugar de ejecutar todas las
estrategias simultáneamente, el sistema emplea algún criterio para conmutar
entre ellas.
- Mixto (Mixed): Reúne en una misma recomendación productos que han sido
sugeridos mediante las diferentes estrategias implementadas en el sistema
híbrido.
- Combinación de características (Feature combination): Reúne en un único
conjunto los datos que utilizan las diferentes estrategias de personalización,
y con éste se ejecuta un solo algoritmo de recomendación. Por ejemplo, si se
combinan los métodos basados en contenido y el filtrado colaborativo, este
esquema podría utilizar la información colaborativa (clasificaciones de los
usuarios) como una característica más de las preferencias de los usuarios,
sobre las que finalmente se ejecutaría el filtrado basado en contenido.
- Cascada (Cascade): Funciona en dos etapas: primero se ejecuta una de las
estrategias de recomendación sobre las preferencias del usuario, obteniendo un
primer conjunto de productos candidatos a ser incluidos en la recomendación
final. A continuación, una segunda estrategia refina la recomendación y
selecciona sólo algunas de las sugerencias obtenidas en la primera etapa.
- Incorporación de características (Feature augmentation): En este esquema,
una de las estrategias se emplea para calcular una clasificación para un
producto concreto. A continuación, esa información se incorpora como dato de
entrada para las siguientes técnicas de recomendación. En otras palabras, la
salida de una de las estrategias de recomendación se utiliza como entrada en
las siguientes. La diferencia fundamental entre este esquema híbrido y el
modelo en cascada, es que en este último la segunda estrategia sólo trabaja
sobre el conjunto de productos candidatos obtenidos por la primera de ellas,
prescindiendo de cualquier tipo de información adicional calculada por
ésta. Por el contrario, en el modelo basado en incorporación de
características, toda la información que proporcione la primera de las
técnicas, se utiliza en la(s) siguiente(s).
7. Metanivel (Meta-level): En este caso, el modelo completo generado por una de
las estrategias se utiliza como entrada en las restantes. La diferencia
fundamental entre este sistema híbrido y el basado en incorporación de
características, es que en este último el modelo aprendido sólo se utiliza para
generar características que se usan como entrada en las siguientes estrategias,
mientras que en el híbrido de metanivel se utiliza todo el modelo como dato de
entrada. Todos los enfoques de personalización revisados en esta sección basan
sus recomendaciones en la inferencia de conocimiento a partir de las
preferencias de los usuarios activos. Sin embargo, ninguno de ellos infiere
dicho conocimiento a partir de un proceso de razonamiento basado en descubrir
relaciones semánticas complejas entre dichas preferencias y los contenidos
considerados durante el proceso de recomendación. Este tipo de razonamiento
semántico, inspirado en la filosofía de la Web Semántica, requiere representar
el conocimiento sobre el dominio de aplicación del sistema y descubrir
relaciones complejas entre las entidades formalizadas en el mismo. Para inferir
las mencionadas relaciones semánticas, los recomendadores necesitan disponer de
metodologías para la consulta de las bases de conocimiento y la recuperación de
información personalizada desde las mismas.
Caracterización de los usuarios: Perfiles de Usuario
Estrategias para el modelado de usuarios
Construir perfiles precisos es una tarea clave para asegurar el éxito de las
recomendaciones, consiguiendo de esta forma reforzar la confianza del usuario
en el sistema de personalización. Para los diferentes dominios de aplicación
en los que se emplean herramientas de personalización, se han propuesto
diferentes estrategias para representar perfiles de usuario, entre las que cabe
destacar:
- Historiales de consumo: Adoptada en varios dominios de aplicación, esta
estrategia modela los perfiles de usuario a través de registros históricos que
almacenan los productos (libros, páginas web, etc.) que ha consumido cada
usuario junto con el interés mostrado por cada uno de ellos.
- Vectores de características: Esta estrategia, vinculada al dominio de
recuperación de información en la web, representa cada documento consultado por
un usuario mediante un vector de características (normalmente, palabras o
conceptos) que tienen un valor asociado (booleano o real). La premisa
fundamental en que se basa esta estrategia es que dos productos son similares
cuando sus respectivos vectores de características son muy parecidos.
- Matrices de clasificaciones: Utilizan matrices para representar los
perfiles de los usuarios. La matriz, que tiene tantas filas como usuarios haya
registrados en el sistema y tantas columnas como productos disponibles,
almacena en cada posición el nivel de interés de los usuarios por cada uno de
los productos.
- Características demográficas: Los perfiles de usuario son registros que
contienen los datos personales (edad, sexo, estado civil, etc.) de cada
usuario. Estas características demográficas se usan para identificar tanto el
tipo de usuario que ha llegado al sistema, como las recomendaciones que han
interesado a otros usuarios con datos similares a los suyos. La principal
ventaja de esta técnica es que no es necesario aplicar ningún mecanismo para
aprender sobre las preferencias de los usuarios, toda vez que son ellos los que
proporcionan toda la información. Sin embargo, esta ventaja se convierte
también en su principal inconveniente por la dificultad que supone aplicar esta
estrategia en un sistema real, por no estar muchas veces los usuarios
dispuestos a revelar datos de carácter personal, ni a rellenar largos y
tediosos formularios para poder empezar a recibir recomendaciones del sistema.
- Redes semánticas: Las redes semánticas permiten expresar conocimiento,
empleando conceptos y propiedades y relaciones jerárquicas entre ellos. Cada
concepto es un nodo de la red, las relaciones jerárquicas son enlaces is-a
entre conceptos, y las propiedades se establecen entre dos nodos a través de
enlaces convenientemente etiquetados. En algunas ocasiones, se añaden a los
nodos y a las relaciones pesos numéricos para identificar el nivel de interés
concreto de cada usuario en ellos.
- Redes asociativas: Al igual que las redes semánticas, las redes
asociativas representan diferentes conceptos y relaciones entre conceptos
mediante nodos y enlaces. A diferencia de las redes semánticas, los enlaces no
tienen que estar necesariamente etiquetados. En algunos casos, la etiqueta
semántica, característica de las redes semánticas, se sustituye por un peso
numérico que cuantifica la fuerza de la relación existente entre los nodos
conectados.
- Modelos basados en clasificadores: Los clasificadores son modelos
computacionales que asignan categorías específicas a cada una de las entradas
que se le presentan. En el caso de sistemas de recomendación de contenidos, las
entradas contienen información sobre los productos objetivo y las preferencias
de los usuarios activos, y las categorías de calidad deciden si estos productos
deben o no sugerirse a dichos usuarios. Los clasificadores están basados en
diferentes técnicas como redes bayesianas, árboles de decisión, reglas de
aprendizaje inductivo o redes neuronales.
Métodos para la creación de perfiles iniciales
Una vez decidido el modelo de representación de las preferencias de los
usuarios activos, es necesario recurrir a mecanismos que permitan inicializar
sus perfiles personales. Al respecto, en la literatura podemos encontrar
mecanismos de diversa naturaleza, entre los que cabe destacar por su mayor
importancia:
- Inicialización manual de los perfiles: Algunos sistemas exigen a los
usuarios una descripción explícita de sus intereses personales para construir
su perfil inicial. Si bien esta técnica asegura una precisión máxima en lo que
al modelado de preferencias se refiere, su principal limitación es el esfuerzo
que deben asumir los usuarios a la hora de rellenar largos y tediosos
formularios cuando se registran por primera vez en el sistema.
- Inicialización semiautomática mediante estereotipos: Esta técnica se basa
en definir diferentes categorías genéricas a las que pueden pertenecer los
usuarios, en función de sus intereses y datos personales. De esta forma, cuando
llega un nuevo usuario al sistema, éste debe proporcionar una serie de datos
demográficos (por ejemplo, sexo, edad, ocupación, aficiones, intereses
generales, etc.) que permitirán asignarle un estereotipo que se usará como su
perfil inicial. Por su naturaleza, este mecanismo de creación de perfiles
iniciales suele ir acompañado del método de representación basado en
características demográficas, descrito anteriormente.
Al igual que el método de inicialización manual, la principal debilidad de esta
técnica surge de la dificultad que supone conseguir este tipo de información
por parte de los usuarios, no siempre dispuestos a desvelar datos de carácter
personal. A pesar de ello, el modelado de usuarios basado en estereotipos se ha
aplicado con éxito en el sistema LifeStyle Finder, que sugiere diferentes
productos comerciales a los usuarios, en función de sus características
personales y de los intereses de otros que comparten su estereotipo; y la guía
de programación de TV personalizada PPG, en la que a los espectadores se les
asigna un estereotipo inicial en función de los intereses televisivos que hayan
declarado (género, temática, canal, franja horaria preferente para ver TV,
etc.).
- Inicialización semiautomática mediante conjuntos de entrenamiento: Algunos
sistemas presentan un conjunto de productos a los usuarios para que
identifiquen aquellos que les interesan y aquellos que no son relevantes para
ellos. A partir de esta información, el sistema construye un conjunto de
entrenamiento que se procesa (generalmente) mediante alguno de los
clasificadores citados anteriormente.
La principal limitación de este mecanismo es la identificación de los ejemplos
presentados a los usuarios, dado que éstos deben ser suficientemente
representativos para así garantizar recomendaciones precisas.
Entre los sistemas recomendadores que utilizan conjuntos de entrenamiento para
definir perfiles iniciales, podemos destacar News Weeder, ACR News, PSUN y
NewT, que seleccionan noticias personalizas para sus usuarios; la herramienta
de filtrado de correos electrónicos Re:Agent, y los recomendadores Ringo y
Movielens cuyos ámbitos son la música y la TV personalizada, respectivamente.
- Reconocimiento automático de las preferencias del usuario: En algunos
recomendadores no es preciso crear un perfil inicial para cada usuario activo,
por ser las preferencias de un usuario reconocidas de forma automática a medida
que interactúa con el sistema. Por su propia naturaleza, esta técnica se ha
implantado con gran éxito en el dominio de las herramientas de personalización
Web, en las que las recomendaciones son elaboradas a partir del historial de
navegación de los usuarios. Algunos ejemplos de este tipo de recomendadores
son WebSell, Fab y Webmate.
Técnicas para que los usuarios proporcionen al sistema información de
relevancia sobre las sugerencias ofrecidas
El término realimentación de relevancia identifica la información que los
usuarios proporcionan al sistema recomendador al evaluar las recomendaciones
que reciben. Gracias a esta información, el sistema puede modificar los
perfiles de los usuarios, y así acelerar la convergencia entre los intereses
reales de los usuarios y las sugerencias que se les ofrecerán en el futuro.
Las herramientas de personalización recurren a diversos métodos para obtener
esta valiosa información. El más sencillo y directo de todos ellos es aquel en
el que el propio usuario declara explícitamente su interés/desinterés en
relación a cada producto sugerido. Una solución mejorada con respecto a ésta
consiste en inferir dicha información a partir de la interacción entre el
usuario y el sistema. Por último, algunos sistemas optan por un enfoque híbrido
que combina los dos modelos anteriores:
- Sistemas recomendadores sin realimentación: En la literatura se pueden
encontrar herramientas de recomendación que no actualizan automáticamente los
perfiles a lo largo del tiempo, sino que delegan esta responsabilidad en los
propios usuarios. Es obvio que este tipo de enfoques no necesitan la
realimentación de relevancia, sin embargo, obligan al usuario a asumir un rol
activo no siempre deseable.
- Realimentación explícita: Con este enfoque es necesario que sean los
usuarios quienes proporcionen explícitamente la realimentación de
relevancia. Para este fin, se han definido diferentes métodos:
- En algunos sistemas los usuarios simplemente clasifican los productos como
interesantes o no interesantes. Como ejemplos más representativos
destacamos el recomendador Web Webmate y las herramientas de filtrado de
correo electrónico SIFT Netnews y NewT.
- Otros enfoques requieren que sus usuarios definan un nivel de interés
concreto. Es el enfoque explícito más extendido, adoptado en multitud de
herramientas de personalización: Amazon, los recomendadores Web
Amalthaea, ifWeb y Syskill & Webert, los sistemas de filtrado de noticias
personalizadas INFOrmer y PSUN, el recomendador de música Ringo y los
sistemas de TV personalizada Movielens y Recommender.
- Por último, existen sistemas en los que los usuarios proporcionan
realimentación mediante comentarios textuales. Este es el caso del
recomendador de noticias personalizadas Grouplens y el sistema de filtrado de
correo electrónico Tapestry.
- Realimentación implícita: La realimentación de relevancia puede ser
inferida por el sistema recomendador a partir de las acciones que lleva a cabo
el usuario. Dependiendo del dominio de aplicación de cada sistema, se emplean
diferentes indicativos para obtener dicha realimentación y, en consecuencia,
modificar los perfiles de los usuarios activos: los enlaces por los que éstos
han navegado, su historial de consumo (por ejemplo, productos comprados
mediante comercio electrónico), su historial de navegación, el tiempo empleado
en ver un programa de TV o en consultar una determinada página Web,
etc. Además, ciertas acciones de los usuarios también pueden ser útiles a la
hora de aprender conocimiento adicional sobre sus preferencias: guardar e
imprimir un documento, marcar una página Web, minimizar la ventana en la que
ésta se visualiza, ordenar la grabación de un programa de TV, avanzar,
retroceder o detener su reproducción, etc.
- Realimentación híbrida: La mayoría de los enfoques propuestos optan por un
modelo híbrido, en el que la realimentación inferida por el propio sistema es
completada con las clasificaciones explícitas de los usuarios activos. De esta
forma, es posible aunar las ventajas de ambos métodos, aprovechando tanto la
precisión de la técnica explícita, como el mínimo esfuerzo requerido a los
usuarios en el modelo implícito. Ejemplos de herramientas recomendadotas que
implementas estrategias híbridas de realimentación son LifeStyle Finder,
Anatagonomy, Tapestry, Grouplens, y los recomendadores de comercio electrónico
CDNow y Amazon.
Técnicas para la adaptación del perfil de usuario
En general, las preferencias de los usuarios activos en un sistema recomendador
variarán a lo largo del tiempo, de ahí que la realimentación de relevancia sea
un elemento clave a la hora de reflejar sus nuevos intereses y/o
necesidades. Conscientes de esta evolución, se han propuesto diferentes métodos
para poder adaptar los perfiles de los usuarios a sus nuevas preferencias,
eliminando aquellas que han quedado obsoletas. Entre estos enfoques podemos
destacar por su importancia los siguientes:
- Actualización manual por parte de los usuarios: Algunos sistemas exigen
que los usuarios activos modifiquen sus propios perfiles, incorporando así los
posibles cambios que hayan sufrido sus preferencias desde la última interacción
con la herramienta de recomendación. Esta estrategia tiene serias limitaciones,
debidas no sólo a la incomodidad que supone para los usuarios, obligados a
participar activamente en el sistema, sino también a que la actualización
manual es completamente inviable cuando las preferencias varían con mucha
frecuencia.
- Incorporación de nueva información al perfil: El enfoque más extendido
entre los sistemas recomendadores propuestos en la literatura consiste en
añadir nueva información a los perfiles de los usuarios activos, obtenida a
partir de la realimentación de relevancia. Su principal ventaja es que permite
que los perfiles se adapten rápida y fácilmente a la evolución en las
preferencias de los usuarios. Sin embargo, no contempla ningún mecanismo para
que el sistema olvide los intereses que éstos tenían en el pasado.
- Función de olvido gradual: La función de olvido gradual asigna un peso a
cada producto definido en el perfil del usuario activo, con un valor que
dependerá de su localización temporal. Así, cuando el sistema añade un nuevo
producto, le asocia un peso de valor 1 y decrementa los índices de los
productos que ya estaban almacenados en el perfil. De esta forma, las
preferencias más recientes tendrán asociadas un peso elevado, y por ello serán
más relevantes, ya que reflejan los intereses actuales del usuario.
Selección natural de ecosistemas de agentes: Asociado tradicionalmente a
aquellos sistemas en los que un conjunto de agentes cooperan e interactúan en
un determinado ecosistema. En un sistema de personalización, la evolución del
ecosistema se basa en el siguiente principio: aquellos agentes que ofrecen las
recomendaciones más precisas se reproducen, mientras que el resto son
destruidos. Este tipo de técnicas permiten que el recomendador se adapte a las
nuevas preferencias de los usuarios activos, sin más que eliminar aquellos
agentes que utilizan sus intereses pasados.
DVB-H
El Digital Video Broadcasting (DVB), iniciado en 1992 como iniciativa europea,
es un consorcio liderado por la industria y formado por casi 270 empresas de
unos 35 países que aglutina empresas dedicadas a la radiodifusión, fabricantes,
operadores de red, desarrolladores de software, organismos reguladores, entre
otras. El consorcio está orientado al desarrollo de estándares para el
despliegue global de televisión digital y servicios de datos. Las
especificaciones de este consorcio se convierten en estándares gracias a la
actuación de organizaciones como ETSI ó CENELEC. Una vez aceptados, los
estándares son promocionados para su adopción y posterior uso por cualquier
país del mundo y responden a una necesidad específica del mercado de la
difusión digital. De entre los estándares desarrollados por el consorcio
destaca, en cuanto a su vinculación con el presente proyecto, el estándar DVB-H
(Digital Video Broadcasting Handheld) para la difusión de contenidos para
dispositivos móviles. Está basado en el estándar DVB-T (para la difusión por
radiofrecuencia) y surge porque éste último presentaba problemas específicos de
los receptores en movimiento:
- Batería reducida: DVB-T precisa de elevados consumos de batería para las
capacidades que podemos encontrar en los dispositivos móviles.
- Una única antena de recepción: DVB-T no opera adecuadamente en estas
condiciones.
DVB-H introduce una serie de cambios técnicos con respecto a DVB-T para
adecuarse a las características de los dispositivos móviles, siendo quizá el
concepto de time-slicing el más importante, y el que marca una gran diferencia
con DVB-T. La funcionalidad básica del timeslicing es la de enviar los datos en
ráfagas que son almacenadas en un buffer y posteriormente reproducidas, por lo
que el receptor sólo está encendido cuando los datos relevantes están
disponibles, logrando así un aumento considerable de la vida de la
batería. Adicionalmente, DVB-T incorpora otras mejoras técnicas, como la
segmentación temporal para permitir el traspaso de frecuencias continuo y sin
interrupciones o la corrección de errores en recepción para los datos con
encapsulación multiprocolo (MPE-FEC), con el fin de mejorar la relación
señal/ruido y el comportamiento Doppler en los canales móviles.
Finalmente, los datos se envían con la tecnología IPDC (IP Datacast) que ofrece
transmisiones rápidas (el ancho de banda puede ser de hasta 22Mb/s para
recepción fija) y fiables. Estos servicios IP se pueden transmitir dentro de
los multiplexores de DVB junto con los programas de televisión digital. La
figura 1 representa los principales componentes de un sistema de
transmisión-recepción DVB-H teniendo en cuenta que está enmarcado dentro de la
infraestructura existente para la provisión de servicios DVB-T:
IP Datacast (IPDC) y DVB-H
IP Datacast es un sistema extremo a extremo para la entrega de cualquier tipo
de contenidos digitales mediante el uso de mecanismos IP. Éste fue diseñado
para que millares de receptores dentro del área de cobertura del transmisor
pudieran recibir su señal y por tanto la recepción masiva de servicios de
datos.
En este tipo de comunicación el contenido se difunde simultáneamente a
múltiples receptores al contrario de lo que ocurre en la comunicación
tradicional de Internet en la que el usuario debe solicitar el contenido
deseado. La idea es poder difundir cualquier tipo de información que pueda ser
enviado por la red (Internet), pero muchos servicios IP no están diseñados para
ser entregados de una manera unidireccional, como los que usan el protocolo
TCP, por lo que estos servicios no pueden ser difundidos o tendrían que ser
tratados de una manera diferente. Por el contrario existen muchos servicios
basados en UDP que sí podrían usar esta tecnología.
IPDC es una plataforma para la convergencia de servicios entre el mundo móvil y
el de difusión ya que, por un lado permite la comunicación unidireccional
(basada en DVB) y, por otro, permite la comunicación bidireccional móvil. Así,
un sistema IPDC incluirá todos aquellos elementos típicos de un escenario de
provisión de servicios DVB-H más todas aquellas plataformas mediante las cuales
puedan proporcionarse el resto de funcionalidades.
Los principales elementos funcionales que componen una arquitectura IPDC son
los que detallamos a continuación:
- Terminal. Desde la red DVB-H se reciben las transmisiones IPDC, y la
interactividad con el sistema se da a través de la red móvil.
- Subsistema de Gestión del Servicio. Recibe información desde el subsistema
de aprovisionamiento que agrega a la ESG y proporciona soporte en la protección
del servicio (derechos de acceso al servicio o contenido)
- Subsistema de aprovisionamiento. Se encarga de agregar y entregar, vía
difusión, servicios y contenidos proporcionando interactividad, soporte en la
protección de contenidos (cifrado) así como la transcodificación de los
formatos de los contenidos.
- Subsistema de Comercio. Se encarga de la coordinación de las transacciones
comerciales con el usuario final: autentica al usuario, negocia el precio y la
selección de los servicios, actúa de intermediario en los pagos, entrega los
derechos de acceso a servicios y contenidos, etc. Esta funcionalidad puede
recaer en una entidad externa al subsistema, como pudiera ser la red móvil para
temas de autenticación y un sistema DRM externo para los derechos de acceso.
- Encapsulador IP. Este subsistema se encarga de encapsular el trafico IP en
los flujos de transporte DVB-H, de realizar el Time Slicing y de realizar el
MPE-FEC.
Electronic Service Guide (ESG)
La ESG permite el acceso a los
contenidos que se están difundiendo por la red DVB-H. El modelo de datos de la
ESG, definido por el consorcio DVB, se basa en un esquema XML, tal y como se
indica en la siguiente figura.
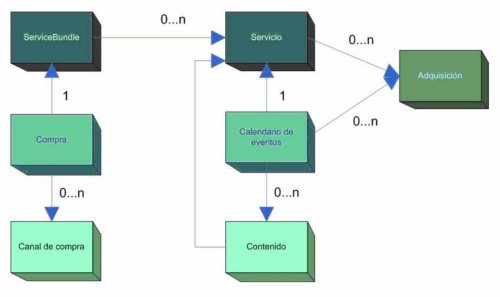
- Servicio. Describe un servicio IPDC proporcionando todos los parámetros
que lo caracterizan como son el nombre del servicio, el número asignado al
servicio, el logotipo, una descripción, el género del servicio, el tipo (stream
o descarga), la clasificación por edades, el idioma, el proveedor del servicio,
una referencia al bloque de datos sobre la adquisición del servicio,
referencias al material relacionado con el servicio, datos privados, un
identificador único del servicio, un campo para indicar si el contenido está
protegido y otro para indicar si se protege mediante técnicas de scrambling.
- ServiceBundle. Grupo de objetos ofrecidos al usuario en forma de
servicios. Este agrupamiento puede usarse para ligar información de compra o
añadir información en el contexto del grupo. Este fragmento maneja datos como
nombre del bundle, proveedor, título del servicio relacionado, descripción,
genero, referencia al servicio, clasificación por edades, material relacionado
y un ID único del conjunto.
- Contenido. Define un contenido con independencia de su formato o forma de
distribución. Éste se define con un título, una referencia a un sonido o imagen
que sirva de título para presentarlo, una referencia al servicio que lo
contenga, una sinopsis, unas palabras clave, un género, un tipo de contenido,
una clasificación por edades, un idioma, un idioma de subtítulos, un idioma de
signos, una lista de créditos, una referencia a material relacionado, una
duración, un campo para datos privados y un identificador único.
- Calendario de eventos. Especifica cuándo van a ser distribuidos los
contenidos de un servicio. Para ello se precisa conocer ciertos datos como la
hora de comienzo de un contenido, la hora de fin, la referencia al servicio, la
referencia al contenido, la referencia a los datos de adquisición, la
localización del contenido, si el contenido es en directo o repetido, si está
protegido, si se ha usado scrambling y un identificador único.
- Compra. Contiene la información de compra de un servicio con el objetivo
de ser mostrada al usuario. Además, incluye una referencia a un ServiceBundle
por lo que incluye el precio, tipo de compra (suscripción, pago por visión,
etc.), unidad cuantitativa (hora, día...), rango de cantidad de unidades que se
pueden comprar, descripción, la petición que se debe realizar para iniciar el
proceso de compra, sistema DRM, datos de compra, referencia al canal de compra,
título en forma de imagen o sonido, periodo de validez de la información e
identificador único.
- Canal de compra. Especifica el interfaz por el que el terminal o el
usuario pueden realizar la compra. Maneja datos nombre, descripción, URL del
portal para hacer la compra, información de contacto, título en formato de
imagen o sonido, datos privados y un ID único.
- Adquisición. Contiene información como la descripción del componente y de
la sesión, el MIME-type del contenido, características de adquisición e
identificador de adquisición entre otros, que sirven para la adquisición de
cada contenido y servicio.